Aristotle Learns to Code, Achieving New State-of-the-Art of 96.8% on Code Verification Benchmark
Since Harmonic’s inception, our charter has been to forge the world’s most advanced mathematical reasoning engine. We have made significant progress this year, becoming among the first AI models to achieve Gold-medal level performance at the International Mathematical Olympiad, the most prestigious mathematics competition in the world. And just recently, a beta version of Aristotle was used to solve and formally verify multiple open Erdos problems, which had been unsolved for decades. From the early days of Harmonic, we hypothesized that an AI with superlative mathematical reasoning capabilities would also perform well in other quantitative domains, in particular software engineering. Today we are excited to share how this is going.
Developed by researchers at UC Berkeley and Meta, VERINA (Verifiable Code Generation Arena) was built to serve as a high quality means of benchmarking verifiable code generation. Code generation has quickly become one of the most powerful use cases of LLM’s, yet verifying correctness using informal methods is costly and manual, causing the same verification bottleneck Aristotle is already beginning to address for mathematics. You can read more about the methodology behind VERINA on their website.
We recently put Aristotle to the test against the VERINA benchmark to test our capabilities at verifying code-specification alignment. Out of the 189 formal specifications in the benchmark, Aristotle proved 160 to be correct and 23 to be false, resolving 96.8% of the problems in the benchmark.
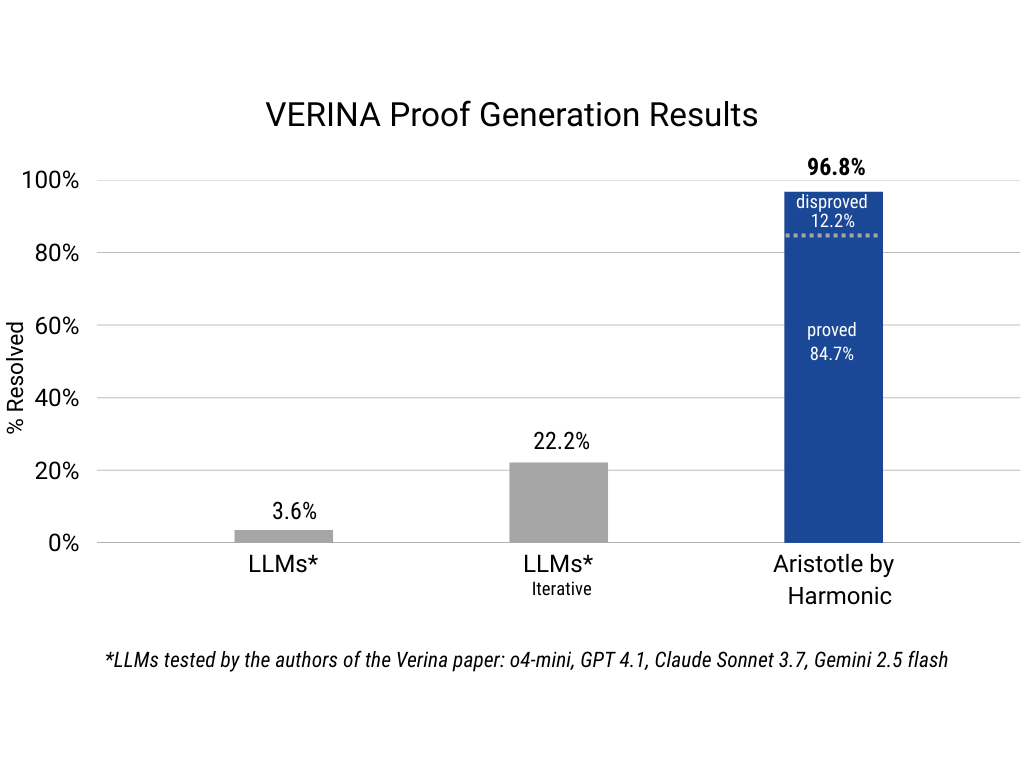
Aristotle significantly outperforms leading LLMs that were tested upon creation of the benchmark in proving the correctness of these algorithm implementations. Here are a few examples we found interesting:
• A proof that an in-place implementation of selection sort is a valid sorting algorithm.
• A proof of the correctness of an implementation of run-length encoding of a string.
• A proof of an algorithm calculating the length of the longest increasing subsequence of a list of integers.
• A proof that an algorithm calculating the k-most frequent entries to a list has a bug.
Let's look at the last two examples in more detail. Every entry in the benchmark, as we have used it, comes with four sections: A precondition, which is assumed to hold before executing the algorithm, then the algorithm implementation itself, then a so-called postcondition which is supposed to hold after execution, and finally the proof goal that states the fact every execution that meets the precondition also fulfills the postcondition.
In the example of calculating the longest increasing subsequence, the postcondition in Lean looks as follows; it is a predicate on inputs to the algorithm, its result, and the precondition, which in this case is vacuous:
def longestIncreasingSubseqLength_postcond (xs : List Int) (result: Nat)
(h_precond : longestIncreasingSubseqLength_precond (xs)) : Prop :=
-- !benchmark @start postcond
let allSubseq := (xs.foldl fun acc x => acc ++ acc.map (fun sub => x :: sub))
[[]] |>.map List.reverse
let increasingSubseqLens := allSubseq.filter
(fun l => List.Pairwise (· < ·) l) |>.map (·.length)
increasingSubseqLens.contains result ∧ increasingSubseqLens.all (· ≤ result)
In natural language, the condition reads as follows: take all subsequences of xs, apply a filter to get a list of only those subsequences which are strictly increasing, then result should be contained in those and all of them should have a length less or equal to the one of result.
Besides proving positive results, it also identified ones which were not true, by finding counterexamples to the statements: For the problem verina_advanced_76, which involves the verification of a function that selects the k most frequent integers in a list, the postcondition is incorrectly stated in a way that sometimes fail to capture the intended meaning if several integers are contained the same number of times:
-- Elements in result are ordered by decreasing frequency
List.Pairwise (fun (x, i) (y, j) =>
i < j → nums.count x > nums.count y ∨
(nums.count x == nums.count y ∧ nums.idxOf x < nums.idxOf y)
) result.zipIdx
Our model finds this inconsistency and provides a counterexample that proves that the given implelementation does not imply the given postcondition:
theorem topKFrequent_spec_satisfied (nums: List Int) (k: Nat)
(h_precond : topKFrequent_precond (nums) (k)) :
topKFrequent_postcond (nums) (k) (topKFrequent (nums) (k) h_precond) h_precond := by
by_contra h;
have := h_precond;
revert h;
apply not_not.mpr;
-- Wait, there's a mistake. We can actually prove the opposite.
negate_state;
-- Proof starts here:
-- Let's choose `nums = [4, 1, 2, 1, 4]` and `k = 2`.
use [4, 1, 2, 1, 4], 2;
native_decide +revert
These disproved results provide useful feedback to developers signaling either their implementation or their specifications are wrong as seen in the case above.
We are inspired by these preliminary, yet state-of-the-art results as we move rapidly to expand Aristotle’s powerful formal verifiable capabilities into more domains.
This performance against the VERINA benchmark was achieved using the version of Aristotle that is available to the public in our API. You can sign up for access to begin using Aristotle’s advanced reasoning capabilities today.